안녕하세요 소신입니다.

ResNeXt는 ResNet에 Inception개념과 AlexNet 개념을 응용한 모델입니다 !
뭔가 더 복잡하게 해서 성능이 올라간것처럼 보이지만
같은 복잡도 대비 성능을 끌어올린 모델입니다.
# ResNet → ResNeXt

최신 연구의 방향은 Data를 변형하는 Feature Engineering에서 Network 즉, 모델을 Engineering로 바뀌었습니다.
Channel의 개수나 Filter의 크기, strides를 변형하며 같은 데이터를 넣어도 더 예측력있는 모델을 만드는 것이죠
그래서 ResNet은 Inception Model의
Split - Transform - Merge 전략을 ResNet에 접목하게 됩니다.
x를 나눠 여러 weight와 곱한뒤 합치는 것이죠
네트워크층에 접목하면, 하나의 큰 Convolutional Layer를
여러개의 작은 Convolutional Layer로 나눠서 계산된 결과를 합치는 겁니다.
ResNeXt-50 (32x4d) - Cardinality 32, width 4
Cardinality는 하나의 Conv. Net을 몇개로 나눌 것인지? (ResNeXt에선 32개)
d는 width, 하나의 Conv. Net의 Channel입니다. (4로 나뉘게 됩니다.)
# 관련 연구

이러한 모델이 어떻게 나왔는지 살펴보면,
1. GoogLeNet의 Inception 모델의 Multi-branch convolutional networks
- Inception Model은 위에서 살펴봤듯이 Split-Transform-Merge가 기본 전략입니다.
2. AlexNet 모델의 Grouped Convolutions
- AlexNet 논문에서 GPU 성능때문에 Convolutional Net을 두개로 나눠서 병렬처리한 것을 알 수 있습니다.
- 이를 응용해서 Conv. Net을 더 잘게 쪼개고, 연산하는 방향으로 발전합니다.
3. Compressing - 하나의 네트워크에 몰빵한다는 개념으로, 위의 두 개념과 반대됩니다.
4. Ensembling - 그러면 ResNeXt은 앙상블 모델이 아닌가? 하는 생각이 처음에 들었습니다.
- 하지만 생각해보면, 앙상블은 여러 모델의 output을 평균내서 하나를 예측합니다.
- ResNeXt는 모델 안에서 나뉘고 합쳐지고, 가중치 개선도 하나의 모델 안에서 이루어집니다.
- 따라서, 앙상블이라 보기에는 부정확하다는 겁니다.
# 방법론 & 구현

디자인을 한땀한땀 하는 것보다, VGGNet처럼 구조는 Simple하게 가져갔습니다.
ResNet의 Template은 그대로 가져가서 Design만 바꾸게 됩니다.
이것을 구현하는 모델링 방법으로 여러가지가 있었는데,
세 가지 모두 성능은 똑같다고 합니다.
논문에선 구현하기 쉽고 빠른 b를 썼다고 하는데 torch에는 c버전으로 나옵니다.
Downsample: resnet에서 identity (x)의 dimension이 output의 dimension을 맞춰주는 것
Schedule : 학습 중간에 learning rate를 미세하게 조정하면 성능이 좋아집니다.
# 결론
1. 세 가지 Tuning - Layer를 늘리는 것 (Deep), Channel을 늘리는 것(width), Cardinality (분리)
위의 셋 중에 Cardinality가 제일 효과적이었음
※ ResNet200층과 비교했을 때 ResNeXt101층 (32x4d)의 복잡도는 절반임에도 불구하고 성능이 더 좋았음.

# 모델링
def conv_start():
return nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=4),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
def bottleneck_block(in_dim, mid_dim, out_dim, groups=32, down=False):
layers = []
width = mid_dim // 64 * 32 * 4 # bottleneck_width
k = 2 if down else 1
layers.append(nn.Conv2d(in_dim, width, kernel_size=1, stride=k, padding=0))
layers.extend([
nn.BatchNorm2d(width),
nn.ReLU(inplace=True),
nn.Conv2d(width, width, kernel_size=3, stride=1, padding=1, groups=groups),
nn.BatchNorm2d(width),
nn.ReLU(inplace=True),
nn.Conv2d(width, out_dim, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(out_dim),
])
return nn.Sequential(*layers)
class Bottleneck(nn.Module):
def __init__(self, in_dim, mid_dim, out_dim, down:bool = False, starting:bool=False) -> None:
super(Bottleneck, self).__init__()
if starting:
down = False
self.block = bottleneck_block(in_dim, mid_dim, out_dim, down=down)
self.relu = nn.ReLU(inplace=True)
k = 2 if down else 1
conn_layer = nn.Conv2d(in_dim, out_dim, kernel_size=1, stride=k, padding=0) # size 줄어듬
self.changedim = nn.Sequential(conn_layer, nn.BatchNorm2d(out_dim))
def forward(self, x):
identity = self.changedim(x)
x = self.block(x)
x += identity
x = self.relu(x)
return x
def make_layer(in_dim, mid_dim, out_dim, repeats, starting=False):
layers = []
layers.append(Bottleneck(in_dim, mid_dim, out_dim, down=True, starting=starting))
for _ in range(1, repeats):
layers.append(Bottleneck(out_dim, mid_dim, out_dim, down=False))
return nn.Sequential(*layers)
class ResNeXt(nn.Module):
def __init__(self, repeats:list = [3,4,6,3], num_classes=1000):
super(ResNeXt, self).__init__()
self.num_classes = num_classes
self.conv1 = conv_start()
base_dim = 64
self.conv2 = make_layer(base_dim, base_dim, base_dim*4, repeats[0], starting=True)
self.conv3 = make_layer(base_dim*4, base_dim*2, base_dim*8, repeats[1])
self.conv4 = make_layer(base_dim*8, base_dim*4, base_dim*16, repeats[2])
self.conv5 = make_layer(base_dim*16, base_dim*8, base_dim*32, repeats[3])
self.avgpool = nn.AvgPool2d(kernel_size=7, stride=1)
self.classifer = nn.Linear(2048, self.num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.classifer(x)
return x
# resnet = ResNeXt()
# param = list(resnet.parameters())
# print(len(param))
# for i in param:
# print(i.shape)데이터 로드하는것과 학습코드는 ResNet모델과 똑같기 때문에 따로 적지 않았습니다.
바꾼 부분이 한 두줄밖에 없습니다. torch nn의 Conv2d에서 groups를 인자로 받아 나눠주는건 자동으로 해주기 때문에,
bottleneck_block에서 가운데 conv. net의 channel이 resnext에선 2배씩 늘어납니다. (64 → 128)
그래서 width를 새로 계산해주게 됩니다.
Load Data, Training 전체 구현 코드는 아래 Ref에서 참고해주세요 !
# 결론
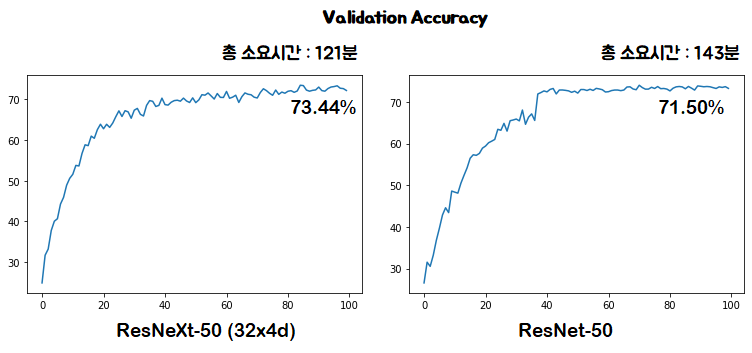
validation set에 대한 정확도도 ResNeXt가 더 높고, 학습 속도도 ResNeXt가 좀 더 빠른 모습을 보입니다.

Loss가 완전히 0에 가까운것도 아닌데 validation set에 대한 정확도가 오히려 높게 나오네요

같은 100에폭을 돌렸을 때, 역시나 50층 보다 정확도는 낮네요
에폭수를 늘리면 좀 더 정확도가 높아질것 같은데 컴퓨팅 자원이 한정되어있어서...

같은 100에폭에서 ResNet-101은 더 일찍 수렴했는데도 불구하고 정확도는 더 낮은 모습을 보입니다.

loss도 아직 0.9정도면 더 내려갈 가능성이 충분해보이구요 !
여기서 확인한 것은, 앙상블이 단일 모델보다 성능이 좋듯이
Conv Net도 딥하고 잘게 분리할수록 성능이 더 좋아지는 것 같습니다.
Ref.
'데이터 분석 > 딥러닝' 카테고리의 다른 글
| [MobileNet] 논문 리뷰 & 구현 (Pytorch) (0) | 2020.12.19 |
|---|---|
| [ResNet] 논문 리뷰 & 구현 (Pytorch) (1) | 2020.12.18 |
| [AlexNet] 논문 리뷰 & 구현 (Pytorch) (1) | 2020.12.16 |