안녕하세요, 소신입니다.

이미지 인식에서 엄청난 반향을 일으켰던 ResNet 입니다.
Residual (잔차)를 학습한다해서 ResNet이라는 이름이 붙었습니다.
# 기존 접근 방식의 문제점을 해결하기 위해 등장한 ResNet

기존 모델들은 Layer를 Deep하게 쌓으면 성능이 좋아질것이라고 했지만,
실제로는 20층 이상부터 Deep할수록 오히려 performance가 낮아지는 현상인 Degradation문제가 발생했습니다.
그래서 ResNet 팀은 예측하려는 y(분류된 모습)가 실제로는 x(분류되기 전 모습)와 같다고 보고,
y-H(x)를 학습하기보다 x-H(x)를 학습하기가 더 쉽고 빠르다는 것이죠
결론적으로 위가 더 좋다는 것은 저 메달이 증명해줬습니다.
Object Detection 대회인 COCO segmentation에서도 좋은 성과를 보여줬구요
# Modeling

ResNet은 결국 input x를 Layer를 지난 output과 합쳐서 ReLU를 진행한 뒤,
그것을 다음 input으로 넣어주는 과정을 반복하는 것입니다.
34층의 경우에는 2개 layer를 지나는 block을 사용합니다
이때, 채널 수가 늘어나고 feature map의 크기가 절반으로 줄어드는 구간이 3번 발생하게 됩니다.
논문에선
A) zero padding
B) 1x1 Convolutional Layer를 활용 (out_channel=input_channel*2 stride=2)
방법을 통해 해결했습니다.
# 구현

Data Augmentation 방법은 AlexNet과 VGGNet을 그대로 활용했습니다
Dropout대신 Batch Normalization을 추가했습니다.
50층 부턴 2 layer 대신 3 layer bottleneck block를 사용했습니다.
가중치 초기화를 거쳐 Optimizing을 VGGNet과 비슷하게 했습니다. iter수가 굉장히 늘었고
Testing은 오히려 간소화해서 10 crop testing을 했습니다.
앙상블은 soft voting !
# Import Package
!pip install -U albumentations
import torch
print(torch.__version__)
import torch.nn as nn
import torch.optim as optim
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
torch.manual_seed(53)
if device == 'cuda':
torch.cuda.manual_seed_all(53)
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from PIL import Image
import numpy as np
import math
############## Load Data ##############
import zipfile
import os
from glob import glob
import json
############## seed ##############
import random
random.seed(53)
############## Transforms ##############
import albumentations as A
from albumentations.pytorch.transforms import ToTensorResNet은 예제 데이터로 돌렸을 때 1에폭부터 수렴하더라구요 역시 갓스넷입니다.
그래서! Kaggle에 있는 ImageNet Mini 데이터를 가져와 돌려봤습니다.
이미지 전처리를 위해 Albumentation 패키지를 썼습니다.
성능이 좋다고는 하는데 아직은 토치 자체 transform이 좀 더 사용하기 쉬운느낌입니다.
Seed를 설정해서 재생산성을 높였고
DataSet과 DataLoader를 Customizing해서 사용하기 위한 것들,
데이터 불러오면서 처리하기 위해 사용하는 패키지들입니다.
# 데이터(이미지) 경로 확인, image id, label 저장
#
if not os.path.exists('/content/data'):
with zipfile.ZipFile('/content/drive/MyDrive/Study_AI/archive.zip') as data_zip:
data_zip.extractall('/content/data')
%cd /content/data/
train_paths = glob(os.path.join('imagenet-mini', 'train', '*', '*.JPEG'))
valid_paths = glob(os.path.join('imagenet-mini', 'val', '*', '*.JPEG'))
%cd /content/drive/MyDrive/Study_AI
idx2label = []
cls2label = {}
with open("./imagenet_class_index.json", "r") as read_file:
class_idx = json.load(read_file)
idx2label = [class_idx[str(k)][1] for k in range(len(class_idx))]
cls2label = {class_idx[str(k)][0]: class_idx[str(k)][1] for k in range(len(class_idx))}
# 이미지별 라벨 숫자로 변환
def get_data(image_dir):
label, image_id = image_dir.split('/')[-2:]
return dict(image_id = image_id.split('.')[0], label = label)
train_list = [get_data(img_dir) for img_dir in train_paths]
valid_list = [get_data(img_dir) for img_dir in valid_paths]구글드라이브에 zip 압축을 풀어주고 imagenet class명을 담은 json파일을 가져왔습니다.
(ref에 링크)
그리고 이미지 이름과 label을 매칭해서 list에 담아줬습니다.
# Albumentations transform 정의
def get_train_transforms():
return A.Compose([
A.CenterCrop(p=1, height=256, width=256),
A.RandomCrop(224, 224), # crop to 227x227 size
A.HorizontalFlip(),
ToTensor(),
])
def get_test_transforms():
return A.Compose([
A.CenterCrop(p=1, height=256, width=256),
A.RandomCrop(224, 224),
ToTensor(),
])전처리 모델로 Albumentations 패키지를 사용했고
비율맞춰서 Resizing하는 것은 Dataset에서 처리를 해줬습니다.
알고보니까 Albumentation ToTensor()에 정규화가 내장되어있더라구요
CenterCrop으로 이미지의 가운데 부분만 가져와서 224x224로 다시 Crop 해주었고,
Train과 Test 따로 transform을 정의했습니다.
# ImageDataSet 정의
#
DIR_TRAIN = '/content/data/imagenet-mini/train'
DIR_VALID = '/content/data/imagenet-mini/val'
minwidth = 256
minheight= 256
class ImageNetDataset(Dataset):
def __init__(self, image_list, mode='TRAIN', transforms=None):
self.images = image_list
self.transforms = transforms
self.mode = mode
# 인덱싱
self.img_ids = {x['image_id'] : i for i,x in enumerate(image_list)}
# 필수
def __len__(self) -> int:
return len(self.images)
def get_indices(self,img_ids):
return [self.img_ids[x] for x in img_ids]
# 필수
def __getitem__(self,index):
record = self.images[index]
image_id = record['image_id']
label = record['label']
if self.mode == 'TRAIN':
image = Image.open(f'{DIR_TRAIN}/{label}/{image_id}.JPEG').convert("RGB")
else:
image = Image.open(f'{DIR_VALID}/{label}/{image_id}.JPEG').convert("RGB")
w, h = image.size
ratio = max(minwidth/w, minheight/h)
image = image.resize((math.ceil(w * ratio), math.ceil(h * ratio)), Image.ANTIALIAS)
image = np.array(image)
label = idx2label.index(cls2label[label])
if self.transforms:
sample = self.transforms(image=image)
image = sample['image']
return image, label, image_id
#
train_set = ImageNetDataset(train_list, mode='TRAIN', transforms=get_train_transforms())
valid_set = ImageNetDataset(valid_list, mode='VALID', transforms=get_test_transforms())Torch DataSet을 Customizing한 클래스입니다.
Train 경로와 Valid 경로를 따로 지정해주었고
__len__과 __getitem__을 필수로 구현해야 되는데
간단하게 설명하면 특정 이미지를 어떻게 가져올건지 정의하는 곳입니다.
Image데이터를 한번에 메모리에 다 올려놓고 연산하면 빠르고 좋겠지만 하드웨어 한계가 있으니
Batch Size만큼만 이미지를 불러와서 메모리에 할당하고 연산하는 방식을 사용합니다.
이미지를 불러와서 비율에 맞춰 resize한 뒤, numpy array로 형변환해주었습니다.
image는 전처리를 진행하면서 torch tensor로 바뀌게 됩니다.
# Data Loader
#
# Torch DataLoader
BATCH_SIZE = 128
# torch tensor를 batch size만큼 묶어줌
def collate_fn(batch):
images, labels, img_ids = zip(*batch)
return torch.cat([img.reshape(-1, 3, 224, 224) for img in images], 0), torch.tensor(labels)
# 데이터를 Torch DataLoader 형식으로 변환
trainloader = DataLoader(train_set, batch_size = BATCH_SIZE,
shuffle=True, num_workers=0, collate_fn = collate_fn)
testloader = DataLoader(valid_set, batch_size = BATCH_SIZE,
shuffle=False, num_workers=0, collate_fn = collate_fn)torch dataset에서 이미지를 불러오면서 tensor로 바꾸는데 반환된 결과값이 tuple로 묶인 tensor더라구요
원하는 모양은 (batch_size, channel(RGB), height, width)이기 때문에 collate_fn으로 바꿔주는 코드를 넣었습니다.
# Modeling

def conv_start():
return nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=4),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)모델의 처음 시작하는 부분입니다. 여기서 224x224x3 image가 56x56x64 image로 변환됩니다.
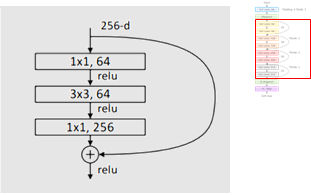
bottleneck block입니다.
def bottleneck_block(in_dim, mid_dim, out_dim, down=False):
layers = []
if down:
layers.append(nn.Conv2d(in_dim, mid_dim, kernel_size=1, stride=2, padding=0))
else:
layers.append(nn.Conv2d(in_dim, mid_dim, kernel_size=1, stride=1, padding=0))
layers.extend([
nn.BatchNorm2d(mid_dim),
nn.ReLU(inplace=True),
nn.Conv2d(mid_dim, mid_dim, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(mid_dim),
nn.ReLU(inplace=True),
nn.Conv2d(mid_dim, out_dim, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(out_dim),
])
return nn.Sequential(*layers)input dimension, mid dimension, output dimension을 받아 convolution network를 쌓고
down인자를받아 input size와 output size가 바뀔 때, stride 값을 변경했습니다.
class Bottleneck(nn.Module):
def __init__(self, in_dim, mid_dim, out_dim, down:bool = False, starting:bool=False) -> None:
super(Bottleneck, self).__init__()
if starting:
down = False
self.block = bottleneck_block(in_dim, mid_dim, out_dim, down=down)
self.relu = nn.ReLU(inplace=True)
if down:
conn_layer = nn.Conv2d(in_dim, out_dim, kernel_size=1, stride=2, padding=0), # size 줄어듬
else:
conn_layer = nn.Conv2d(in_dim, out_dim, kernel_size=1, stride=1, padding=0), # size 줄어들지 않음
self.changedim = nn.Sequential(conn_layer, nn.BatchNorm2d(out_dim))
def forward(self, x):
identity = self.changedim(x)
x = self.block(x)
x += identity
x = self.relu(x)
return x그래서 이부분을 torch nn 모듈로 변환해주고 identity를 output에 더해서 relu를 취한뒤 반환해줍니다.
down sizing이 발생할 때 사이즈를 줄여줍니다.

starting 인자는 맨처음 maxpool을 지나고 56x56x64 image가 그대로 bottleneck의 identity로 들어가기 때문에
down sizing이 일어나지 않아 이를 명시해주고자 추가했습니다.

def make_layer(in_dim, mid_dim, out_dim, repeats, starting=False):
layers = []
layers.append(Bottleneck(in_dim, mid_dim, out_dim, down=True, starting=starting))
for _ in range(1, repeats):
layers.append(Bottleneck(out_dim, mid_dim, out_dim, down=False))
return nn.Sequential(*layers)
반복되는 부분을 계속 추가해주다보면 코드 라인이 너무 길어지기 때문에 위에서
Bottleneck 모듈을 가져와 반복문으로 layer를 쌓아줬습니다.
(50층도 직접 쌓다보면 현타오는데 101층, 152층은...)

class ResNet(nn.Module):
def __init__(self, repeats:list = [3,4,6,3], num_classes=1000):
super(ResNet, self).__init__()
self.num_classes = num_classes
# 1번
self.conv1 = conv_start()
# 2번
base_dim = 64
self.conv2 = make_layer(base_dim, base_dim, base_dim*4, repeats[0], starting=True)
self.conv3 = make_layer(base_dim*4, base_dim*2, base_dim*8, repeats[1])
self.conv4 = make_layer(base_dim*8, base_dim*4, base_dim*16, repeats[2])
self.conv5 = make_layer(base_dim*16, base_dim*8, base_dim*32, repeats[3])
# 3번
self.avgpool = nn.AvgPool2d(kernel_size=7, stride=1)
self.classifer = nn.Linear(2048, self.num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.avgpool(x)
# 3번 2048x1 -> 1x2048
x = x.view(x.size(0), -1)
x = self.classifer(x)
return x위의 과정을 거치면 위의 코드로 ResNet이 구현됩니다.
repeats를 list로 받아 101층, 152층을 쌓기 쉽게 했습니다.
1. 맨처음 시작 부분을 conv_start() 함수를 불러와 쌓아주고
2. conv 2,3,4,5 bottleneck block을 make_layer함수로 불러와 반복해 쌓아줍니다.
3. global avgerage pooling을 지나면 2048x1이 되기 때문에, 1x2048로 바꿔줍니다.
(classifier가 2048 x num_classes 이므로)
softmax는 CrossEntropyLoss에 있기 때문에 제외
# Load Model & Optimizing function
# Load Model
resnet = ResNet(num_classes = 1000)
# resnet = ResNet(repeats=[3,4,23,3], num_classes = 10) # 101 Layer
# resnet = ResNet(repeats=[3,8,36,3], num_classes = 10) # 152 Layer
# resnet.apply(init_weights)
resnet = resnet.to(device)
# Optimize
criterion = nn.CrossEntropyLoss().cuda()
optimizer = optim.SGD(resnet.parameters(),lr=0.01, momentum=0.9,weight_decay=0.0005)ResNet 클래스에서 repeats를 list로 넘겨주면 block을 채워주는 코드입니다.
기본은 50층이고 bottleneck block이 똑같기 때문에 101, 152층으로도 쌓을 수 있습니다.
# Training
# 노트북일 때만 사용
from tqdm.notebook import tqdm
import time
start_time = time.time()
min_loss = int(1e9)
history = {'loss':[], 'val_acc':[]}
for epoch in range(100): # loop over the dataset multiple times
epoch_loss = 0.0
tk0 = tqdm(trainloader, total=len(trainloader),leave=False)
for step, (inputs, labels) in enumerate(tk0, 0):
inputs, labels = inputs.to(device), labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
outputs= resnet(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
# validation
if epoch%10==0:
class_correct = list(0. for i in range(1000))
class_total = list(0. for i in range(1000))
with torch.no_grad():
for data in testloader:
images, labels = data
images = images.cuda()
labels = labels.cuda()
outputs = resnet(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(labels.size()[0]):
label = labels[i].item()
class_correct[label] += c[i].item()
class_total[label] += 1
val_acc = sum(class_correct) / sum(class_total) * 100
else:
val_acc = 0
# print statistics
tqdm.write('[Epoch : %d] train_loss: %.5f val_acc: %.2f Total_elapsed_time: %d 분' %
(epoch + 1, epoch_loss / 272, val_acc, (time.time()-start_time)/60))
history['loss'].append(epoch_loss / 272)
history['val_acc'].append(val_acc)
if epoch in [36, 64, 92]:
for g in optimizer.param_groups:
g['lr']/=10
print('Loss 1/10')
print(time.time()-start_time)
print('Finished Training')Training Code에 계속 무언가를 추가하게 되더라구요 ㅋㅋㅋ
1. Learning Rate 1/10
validation error가 더이상 줄어들지 않을 때 learning rate를 줄이는게 좋은데
우선 100 에폭 중 28, 56 에폭에서 learning rate를 줄여주었습니다.
2. history에 val_acc 추가
그리고 loss뿐 아니라 val_acc도 plot 그려보고 싶어서
history에 loss랑 validation accuracy를 추가해주었습니다.
class 수가 많을수록 오래걸리기 때문에 10에폭마다 계산하게 했습니다.
# 결론

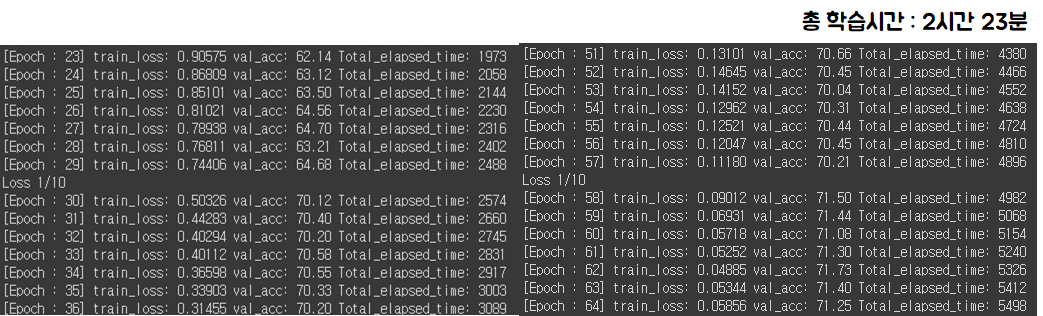
결국 위의 Imagenet mini 데이터는 너무 오래걸려서 STL 10 데이터로 돌림
100 Epoch 학습이 생각보다? 오래걸린다.
ResNet 50은 정말 빠르게 수렴하고 validation 정확도가 71~72%에서 머무르는 경향을 보임
Alexnet은 loss수렴하기까지 오래걸리고 VGGNet은 validation 정확도가 46~47%에서 멈추는데 반면,
ResNet 50의 경우 1에폭부터 빠르게 수렴하는 모습을 보임, 또한 정확도도 빠르게 상승
learning rate를 줄일때마다 validation accuracy가 조금씩 증가함

ResNet 50, 101, 152 처럼 네트워크 층이 늘어날수록 정확도가 충분히 올라가기까지 시간이 좀 걸린다.
Template 방식 - 모델링할 반복되는 부분을 module처럼 사용
확실히 각 층의 개수만 넘겨주면 네트워크를 형성하는 방식이 간단하고 성능 또한 나쁘지 않음
감사합니당
ref.
'데이터 분석 > 딥러닝' 카테고리의 다른 글
| [ResNeXt] 논문 리뷰 & 구현 (Pytorch) (0) | 2020.12.19 |
|---|---|
| [AlexNet] 논문 리뷰 & 구현 (Pytorch) (1) | 2020.12.16 |
| [VGGNet] 논문 리뷰 & 구현 (Pytorch) (1) | 2020.12.16 |