안녕하세요 ! 소신입니다.

AlexNet 논문 리뷰 및 Pytorch 구현입니다.
AlexNet은 2012년 우승한 모델입니다.
이전 모델보다 분류 에러율을 약 10%감소시켰습니다.
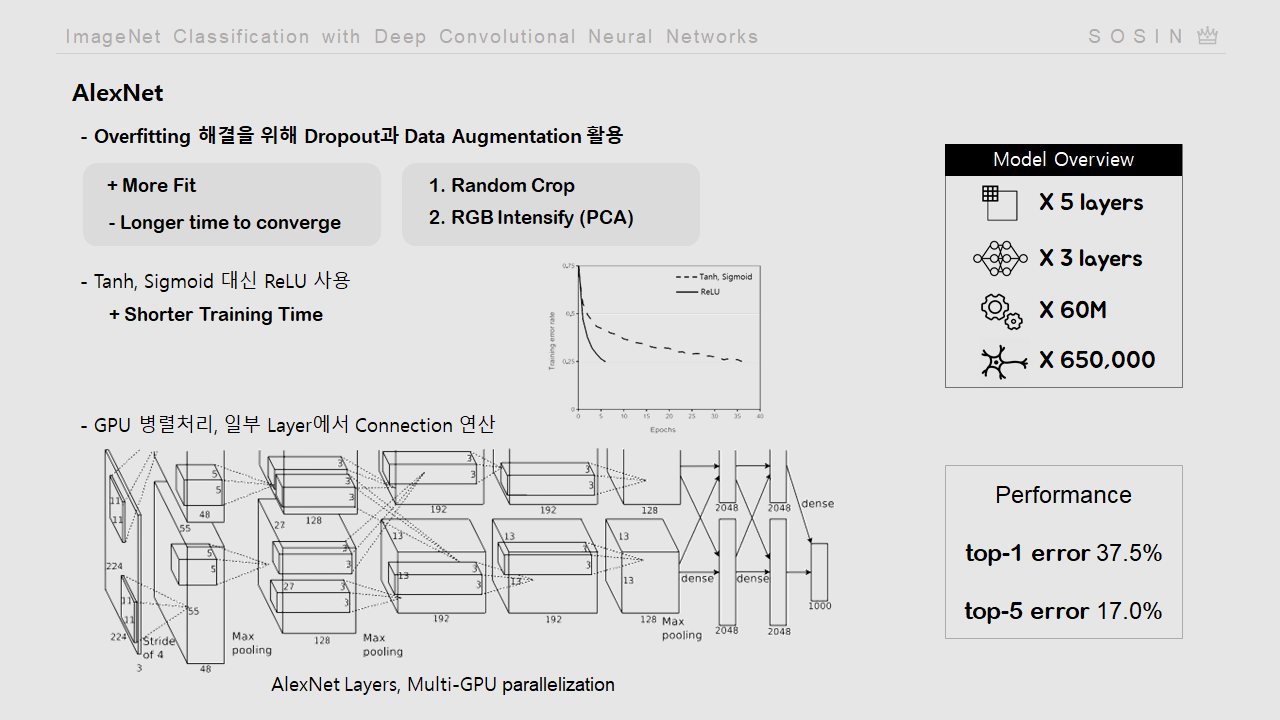
AlexNet은 Overfitting 해결에 집중한 모델입니다.
Dropout과 Data Augmentation을 사용했고
Tanh, Sigmoid 대신 ReLU를 사용해서 학습속도를 높였습니다.
또한, Multi-GPU를 사용해 병렬연산하고 특정 구간마다 연결해 계산했습니다.

AlexNet에선 LRN이라는 Neuron을 사용했습니다.
특정 Filter 한 픽셀의 가중치가 높으면 영향을 받은 Feature Map은 자연스럽게 그 주변의 수치가 높을 것입니다.
따라서 이를 해결하기위해 Filter를 정규화하는 방법을 사용했습니다.
모델 구조는 우측과 같습니다.
병렬처리가 되기 때문에 Channel이 반반 나뉘게 되었고 특정 구간에서 연결연산을 하게됩니다.
논문상에선 어떻게 했다고 나오진 않아서 임의로 구현해보았습니다.

결론적으로, VGGNET과 마찬가지로
AlexNet의 저자도 Convolutional Layer를 줄이면, Performance가 줄어든다는 것을 알았습니다.
그리고 Overlapping Pooling (Stride보다 Kernel Size가 큰 경우)이 약간 더 퍼포먼스가 좋아졌다고 합니다.
Overfitting을 막기 위한 방법으로
1. Data Augmentation
- 이미지의 width, height 중 작은 값을 256으로 Resize (비율 맞춤)
- Train: RandomCrop, Test: 가장자리, 가운데 5개 Crop
- Horizontal Flip
- PCA 사용, RGB의 강도(Intensity) 조절
2. Dropout
- 결론적으로 퍼포먼스는 더 좋았지만, Loss가 수렴하기까지 더 오래걸리게 되었습니다.

논문과 실제 구현하는 부분의 차이입니다.
Multi GPU 모델에서 병렬처리하는 방식이 앙상블가 비슷하겠다는 느낌이어서 두 개를 비교해보기로 했습니다.
할당된 GPU 다쓰고 손가락빨고 있으려니 너무 허전해서 Colab Pro 결제했습니다.
# Transform 정의, 데이터 셋 준비
#
import torch
print(torch.__version__)
##################### Transform, Data Set 준비
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose([
transforms.Resize(256),
transforms.RandomCrop(227),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
trainset = torchvision.datasets.STL10(root='./data', split='train', download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True)
testset = torchvision.datasets.STL10(root='./data', split='test', download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=32, shuffle=False)Transform과 준비한 Data Set입니다.
데이터를 불러오는 코드는 참조 부분에 있는 글의 코드를 가져왔고, Transform만 살짝 수정했습니다.
# AlexNet Modeling
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000, init_weights: bool = True):
super(AlexNet, self).__init__()
self.convnet = nn.Sequential(
# Input Channel (RGB: 3)
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, padding=0, stride=4), # 227 -> 55
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, k=2),
nn.MaxPool2d(kernel_size=3, stride=2), # 55 -> 27
nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, padding=2, stride=1), # 27 -> 27
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, k=2),
nn.MaxPool2d(kernel_size=3, stride=2), # 27 -> 13
nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, padding=1, stride=1),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, k=2),
nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, padding=1, stride=1),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, k=2),
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, padding=1, stride=1),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, k=2),
nn.MaxPool2d(kernel_size=3, stride=2), # 13 -> 6
)
self.fclayer = nn.Sequential(
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes),
)
def forward(self, x:torch.Tensor):
x = self.convnet(x)
x = torch.flatten(x, 1)
x = self.fclayer(x)
return x
단일 GPU라고 가정하고 구성한 모델입니다.
Convolutional Layer 사이에 LRN Layer를 추가해주었습니다.
모델링은 참조에 있는 링크를 참고했습니다.
# AlexNet Multi-GPU Model
# Multi GPU가 아니기때문에 논리구조상 맞도록 Input, Output 조절함
class AlexNetMulti(nn.Module):
def __init__(self, num_classes: int = 1000, init_weights: bool = True):
super(AlexNetMulti, self).__init__()
self.fstblock_1 = nn.Sequential(
# Input Channel (RGB: 3)
nn.Conv2d(in_channels=3, out_channels=48, kernel_size=11, padding=0, stride=4), # 227 -> 55
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, k=2),
nn.MaxPool2d(kernel_size=3, stride=2), # 55 -> 27
nn.Conv2d(in_channels=48, out_channels=128, kernel_size=5, padding=2, stride=1), # 27 -> 27
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, k=2),
nn.MaxPool2d(kernel_size=3, stride=2), # 27 -> 13
)
self.fstblock_2 = nn.Sequential(
# Input Channel (RGB: 3)
nn.Conv2d(in_channels=3, out_channels=48, kernel_size=11, padding=0, stride=4), # 227 -> 55
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, k=2),
nn.MaxPool2d(kernel_size=3, stride=2), # 55 -> 27
nn.Conv2d(in_channels=48, out_channels=128, kernel_size=5, padding=2, stride=1), # 27 -> 27
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, k=2),
nn.MaxPool2d(kernel_size=3, stride=2), # 27 -> 13
)
self.cross_conv_1 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=96, kernel_size=3, padding=1, stride=1),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, k=2),
)
self.cross_conv_2 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=96, kernel_size=3, padding=1, stride=1),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, k=2),
)
self.sndblock_1 = nn.Sequential(
nn.Conv2d(in_channels=192, out_channels=192, kernel_size=3, padding=1, stride=1),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, k=2),
nn.Conv2d(in_channels=192, out_channels=128, kernel_size=3, padding=1, stride=1),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, k=2),
nn.MaxPool2d(kernel_size=3, stride=2), # 13 -> 6
)
self.sndblock_2 = nn.Sequential(
nn.Conv2d(in_channels=192, out_channels=192, kernel_size=3, padding=1, stride=1),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, k=2),
nn.Conv2d(in_channels=192, out_channels=128, kernel_size=3, padding=1, stride=1),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, k=2),
nn.MaxPool2d(kernel_size=3, stride=2), # 13 -> 6
)
self.crossfc1_1 = nn.Sequential(
nn.Linear(128 * 6 * 6, 1024),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5)
)
self.crossfc1_2 = nn.Sequential(
nn.Linear(128 * 6 * 6, 1024),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5)
)
self.crossfc2_1 = nn.Sequential(
nn.Linear(2048, 1024),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5)
)
self.crossfc2_2 = nn.Sequential(
nn.Linear(2048, 1024),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5)
)
self.classifier_1 = nn.Linear(2048, num_classes)
self.classifier_2 = nn.Linear(2048, num_classes)
def forward(self, x:torch.Tensor):
# First Block
x1 = self.fstblock_1(x)
x2 = self.fstblock_2(x)
# Cross
x3 = self.cross_conv_1(x1) # Left Block 1
x4 = self.cross_conv_2(x2) # Left Block 2
x5 = self.cross_conv_1(x1) # Right Block 1
x6 = self.cross_conv_2(x2) # Right Block 2
x1 = torch.cat([x3, x4], 1)
x2 = torch.cat([x5, x6], 1)
# Second Block
x1 = self.sndblock_1(x1)
x2 = self.sndblock_2(x2)
x1 = torch.flatten(x1, 1)
x2 = torch.flatten(x2, 1)
# FC Layer (Cross)
x3 = crossfc1_1(x1) # Left FC 1
x4 = crossfc1_2(x2) # Left FC 2
x5 = crossfc1_1(x1) # Right FC 1
x6 = crossfc1_2(x2) # Right FC 2
x1 = torch.cat([x3, x4], 1)
x2 = torch.cat([x5, x6], 1)
# FC Layer (Cross)
x3 = crossfc2_1(x1) # Left FC 1
x4 = crossfc2_2(x2) # Left FC 2
x5 = crossfc2_1(x1) # Right FC 1
x6 = crossfc2_2(x2) # Right FC 2
x1 = torch.cat([x3, x4], 1)
x2 = torch.cat([x5, x6], 1)
x1 = classifier_1(x1)
x2 = classifier_2(x2)
x = (x1 + x2)/2
return x싱글 GPU지만 Multi GPU라고 가정하고 나뉘거나, Connection될 때를 고려해 논리적으로 구현해보았습니다.
중간에는 각각의 결과를 concatenate하지만, 분류 후에는 두 결과를 더하고 2로 나눠주었습니다.
(어차피 나중에 softmax처리가 되기때문에..)
직접 구현한 멀티 GPU Code는 좀 길어서.. 접어놨습니다.
# Weight Initialization
def init_weights(m):
if type(m) not in [nn.ReLU, nn.LocalResponseNorm, nn.MaxPool2d,
nn.Sequential, nn.Dropout, AlexNet, AlexNetMulti]:
torch.nn.init.normal_(m.weight, 0, 0.01)
m.bias.data.fill_(1)
alexnet = AlexNet(num_classes = 1000)
alexnet.apply(init_weights)
alexnet = alexnet.to(device)
# 파라미터 초기화 확인
# for p in alexnet.parameters():
# print(p)
# break
criterion = nn.CrossEntropyLoss().cuda()
optimizer = optim.SGD(alexnet.parameters(),lr=0.01, momentum=0.9, weight_decay=0.0005)원래 논문에선 Convolutional Layer 중 1, 3번째 레이어만 Bias를 0으로 초기화해주지만
코드짜기 귀찮으니까 그냥 전 Layer 똑같이 초기화해주었습니다.
모델링한 뒤 초기화하고 GPU Device에 넣어주었습니다.
loss function과 optimizer를 구현해주었습니다.
SGD optimizer를 사용했고 lr은 0.01, validation이 감소할때마다 10씩 나눠줬습니다. (90 Epoch 중 총 3번)
momentumm 0.9, weight_dacay는 0.0005를 주었습니다
weight_decay : 오버피팅을 줄이기 위해 가중치가 너무 커지지 않도록 조절하는 것
# Training & Validation
# 노트북일 때만 사용
from tqdm.notebook import tqdm
import time
start_time = time.time()
min_loss = int(1e9)
history = []
for epoch in range(100): # loop over the dataset multiple times
epoch_loss = 0.0
tk0 = tqdm(train_loader, total=len(train_loader),leave=False)
for step, (inputs, labels) in enumerate(tk0, 0):
inputs, labels = inputs.to(device), labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
outputs= alexnet(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
history.append(loss.item())
# validation
class_correct = list(0. for i in range(1000))
class_total = list(0. for i in range(1000))
with torch.no_grad():
for data in valid_loader:
images, labels = data
images = images.cuda()
labels = labels.cuda()
outputs = alexnet(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(labels.size()[0]):
label = labels[i].item()
class_correct[label] += c[i].item()
class_total[label] += 1
# print statistics
tqdm.write('[Epoch : %d] train_loss: %.5f val_acc: %.2f' %
(epoch + 1, epoch_loss / 157, sum(class_correct) / sum(class_total) * 100))
if min_loss < epoch_loss:
count+=1
if count > 10 :
for g in optimizer.param_groups:
g['lr']/=10
else:
min_loss = epoch_loss
count = 0
print(time.time()-start_time)
print('Finished Training')학습함수입니다.
1 Epoch을 돌고나서 validation 데이터에 대해 정확도 검증을 진행한 뒤 통계를 출력합니다.
# 결론
1. SGD로는 learning rate를 0.01, 0.00001로 바꿔봤는데 둘다 200에폭을 돌려도 수렴을 안함, Adam으로 바꾼 뒤 수렴
2. Single GPU 코드는 70에폭에서 수렴하기 시작, 210 에폭에서 validation set의 정확도는 향상되지 않고,
training loss만 줄어드는 구간에 진입함
Multi-GPU 코드는 Adam Optimizer 그대로 사용해도 410에폭까지 돌려도 수렴하지 않음

Multi GPU도 뉴런은 다 연결되어있는데 역전파 과정에서 문제가 있는지 확인 좀 해봐야겠습니다.
혹시 이미 이런상황을 경험하신분은 댓글 달아주시면.. 감사하겠습니다
감사합니당
ref.
'데이터 분석 > 딥러닝' 카테고리의 다른 글
| [ResNeXt] 논문 리뷰 & 구현 (Pytorch) (0) | 2020.12.19 |
|---|---|
| [ResNet] 논문 리뷰 & 구현 (Pytorch) (1) | 2020.12.18 |
| [VGGNet] 논문 리뷰 & 구현 (Pytorch) (1) | 2020.12.16 |