안녕하세요 ! 소신입니다.

YoLo v1에 이은 두번째입니다.
YoLo를 구현하면서 영상처리까지 진행해보고 싶어졌습니다..
Real Time으로 Object Detecting 하는 영상을 보니 구현이 가능하겠다는 생각이 들더군요
주로 작업을 구글 코랩에서 하다보니
이미지 불러오는게 bottleneck인 것 같아서 비교를 한번 해보려고 합니다.
PIL과 cv2 각각 작업을 진행해서 어떤 게 Load가 빠른지 확인해보겠습니다.
그리고 모델을 학습하다보면, early stopping에 대한 필요성이 있었는데,
이것도 구현해보았습니다.
# YOLO v2
이번 버전은 기존 YOLO에 좋은 부품들을 가져와서 열심히 조립한 모델입니다.
1. Batch Normaliztion 사용
- yolo v2에선 모든 Conv Layer에 BN을 적용했고, BN regularization으로 overfitting을 방지했습니다.
2. High resolution classifier
- 기존에 모델에선 Feature map을 추출하는 네트워크가 224x224의 ImageNet에서만 학습했지만, 이번 모델은 448x448의 이미지로도 (10 epochs) 학습했습니다. (결과적으로 mAP가 약 4%가 상승했습니다.)
3. Convolutional with Anchor box
- fc layer를 완전 제거하고 bounding box 예측은 anchor box를 사용했습니다. (mAP 0.3%감소, recall 7% 증가)
- downsampling을 5번, 즉 2**5=32만큼 작아지게 되는데, 416의 size로하면, 13x13이 됩니다. 이렇게 홀수일 경우 가운데 그리드가 4개로 나뉘지 않고 center 하나로 해줄 수 있습니다.
4. Dimension Clusters
- training set의 bounding box로 K-means clustering을 활용, 최적의 Anchor box를 탐색 (5 anchor box)
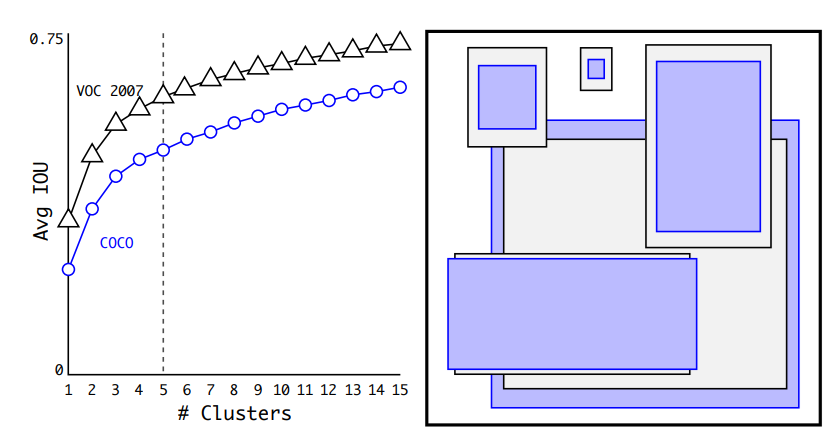
k-means는 clustering 할 때 거리를 기준으로 하는데, 여기서 euclidean을 사용할 경우 box크기에 따른 민감도를 반영하지 못합니다.
따라서, distance metric을 1 - IoU로 주고 k-means를 수행합니다.
기울기 변화를 보시면 기울기가 점점 완만해지는 것을 확인할 수 있고,
anchor가 많아진다는건 결국 complexity가 증가한다는 것이므로 (trade-off) 논문에선 5를 선택했습니다.
정확도 비교
61.0% 5개 Anchor Box 사용 Cluster with IoU
60.9% 9개 Anchor box 사용 Faster R-CNN
5. Direct Location Prediction
YOLO의 모델이 학습 초기에 불안정한 것을 x, y predict에서 발생하는 문제라고 보았습니다.

학습 초기 d, 즉 실제 bounding box와 predicted box의 거리 차이가 크면,
이미지가 해당 grid cell을 벗어난 형태가 됩니다.


이를 조정하기 위해 grid cell 내에서만 이동하도록 식을 변경합니다.
cx, cy는 해당 그리드 셀까지의 거리, 시그마 tx, ty는 해당 gird cell - top left에서의 거리가 됩니다.
따라서 bx, by는 해당 그리드 셀에서만 움직이는 값이 됩니다. (오브젝트의 가운데)
pw, ph라는 미리 정해진 anchor box의 width, height로, 예측한 box의 width, height와 계산하여
b에 대한 수식들로 해당 object의 실제 위치를 조정하게 됩니다.
이를 통해 loss를 계산하면 정확한 coordinate를 학습해나가게 됩니다.
6. Fine-Grained Features - Pass Through
YoLo v2는 ResNet모델에 있는 Identity Mapping 방법을 응용해 사용합니다.

ResNet의 경우 위와 같이 Skip Connection을 사용하는데, YoLo v2에서는
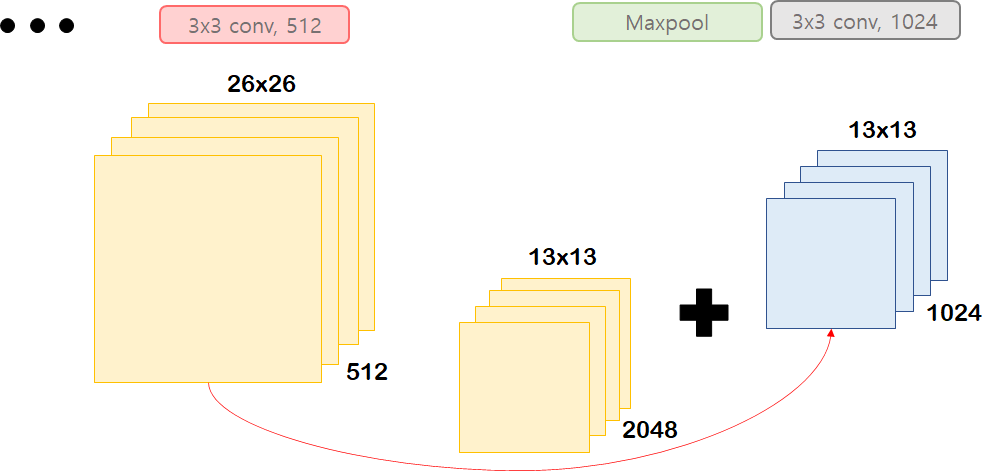
마지막 max pooling 전, feature map의 width와 height를 줄이고,
channel을 늘려 Max pooling 후 conv를 지난 feature map과 합친 뒤, 계산하게 됩니다.
OD 특성 상 큰 feature map에서 object를 파악하기가 쉬운만큼
더 큰 feature map에서 예측한 값들을 가져와서 마지막에 활용하겠다는 것이죠
이를 YOLO v2에선 Pass Through라고 합니다.
# 비교 분석

YOLO v2는 SSD와 비교했을 때 대부분의 면에서 우수한 성과를 달성합니다.
파란 점은 예측하는 이미지의 크기로 구분되어있고,
fps가 낮지만 정확도가 높을수록 큰 이미지, 정확도가 낮지만 fps가 클수록 작은 이미지입니다.
# Backbone Network
기존 VGG16은 FC layer가 무거웠기에 Full Conv Layer로 이루어진 Darknet-19를 사용하게 됩니다.

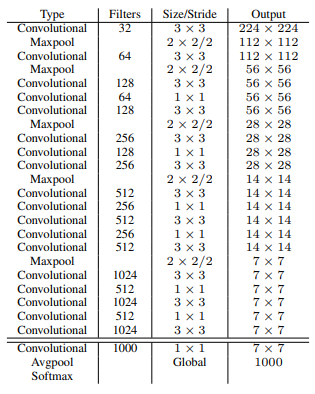
구조에서 볼 수 있듯이 FC layer 대신 GAP를 사용했습니다.
ImageNet을 직접 학습시켰을 때, 88.0% 정확도를 달성한 모델입니다.
160 epochs, SGD - lr: 0.1 polynomial rate decay: 4, weight decay: 5e-4, momentum 0.9
augmentation - random crop, rotation, hue, saturation, exposure shift
# Experiment
ImageNet 데이터를 활용해 학습한 darknet을 448x448의 이미지 크기에 10epochs 학습시켜 fine-tuning합니다.
Darknet의 마지막 conv layer를 제거하고 3x3 1024, 1x1 num_anchors * ( 5 + num_classes )의 layer를 추가합니다.
YoLo v2 = darknet + 3x3 1024, 1x1 125
마지막 Maxpool 전 추출한 feature map을 last conv layer 즉, darknet을 빠져나가기 전
feature map과 concatenate합니다.

이렇게하면 YoLo v2 Model이 됩니다.
Backbone Network를 정말 조금만 수정하고 Object Detection model을 만들었네요
YoLo v2도 160 epoch 학습시켰고,
lr 1e-3으로 시작해 60, 90에서 1/10, weight decay와 momentum은 같습니다.
Augmentation은 random crops, color shifting 등 사용하게 됩니다.
# Stronger
Joint Training Algorithm
Image가 detection용이면 YoLo v2의 loss function을 backpropagation
Image가 classification용이면 해당하는 부분 (backbone network의 conv layer)만 backpropagation
Hierarchical Classifcation
대부분의 데이터셋이 그렇듯 상호 배제 (Mutual Exclusive)가 지켜지는 경우가 많지 않습니다.
상호 독립적이지 않기 때문에, 두 데이터셋을 합치는 것은 쉽지 않습니다. (coco, voc)
이를 조건부확률로 계산해 특정 threshold에 도달하면 해당 object class로 예측하는 방식으로
dataset을 합치는 방법을 사용합니다.


이러한 방법을 통해 한번도 학습하지 않은 label에 대해서도 16.0 mAP를 달성
결론적으로, 새로 발견한 동물이나 데이터가 별로 없는 의상, 장비같은 데이터에도 학습이 가능해집니다.
정말 획기적인 부분이라고 생각합니다.
한번도 보지 않은것에 대해서 단어간 유사성만으로 추상적 판단이 가능해진다는 것이죠.
지금은 단어로 유추하는 정도이지만, 앞으로는 더 괜찮은 방법이 나올 것 같습니다.
# Pytorch 구현
기존 YoLo에서 수정한 부분만 가져왔습니다.
# Dataset 정의
# Make Dataset
class VOCDataset(Dataset):
def __init__(self, data_list, mode='train', transforms=None):
self.data_list = data_list
self.mode = mode
self.transforms = transforms
def __len__(self):
return len(self.data_list)
def __getitem__(self, idx):
record = self.data_list[idx]
img_id = record['image_id']
bboxs = record['bboxs']
labels = record['labels']
img = cv2.imread(image_f.format(self.mode, img_id))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
if self.transforms:
sample = self.transforms(image=img, bboxes=bboxs, category_ids=labels)
image = sample['image']
bboxs = np.asarray(sample['bboxes'])
labels = np.asarray(sample['category_ids'])
if self.mode=='train':
# target = encode(bboxs, labels)
target = np.c_[bboxs, labels].astype(np.float32)
# bgr -> rgb ? r b g
return image, target
else:
return image기존에는 데이터로드할 때 target을 변형했지만, YoLo v2는 anchor를 target 변형에 사용합니다.
괜찮은 loss 코드를 발견해서 여기서는 순서만 맞춰 transforms한 뒤, box와 label을 합쳐 target으로 반환해주었습니다.
Image를 불러오는 패키지도 PIL에서 cv2로 바꿔주었습니다.
# Transformer 정의
def get_train_transforms():
return A.Compose([
A.Resize(*image_size, always_apply=True, p=1),
A.ColorJitter(),
A.Flip(),
ToTensor(),
], bbox_params=A.BboxParams(format='albumentations', label_fields=['category_ids']))
# transformations = Compose([HSVAdjust(), VerticalFlip(), Crop(), Resize(self.image_size)])
def get_test_transforms():
return A.Compose([
A.Resize(*image_size, always_apply=True, p=1),
ToTensor(),
])
# transformations = Compose([Resize(self.image_size)])tansformer도 논문에 나와있는 것을 최대한 반영합니다.
# Dataloader
train_ds = VOCDataset(train_list, transforms=get_train_transforms())
valid_ds = VOCDataset(valid_list, transforms=get_test_transforms())
test_ds = VOCDataset(test_list, mode='test', transforms=get_test_transforms())
# torch tensor를 batch size만큼 묶어줌
def collate_fn(batch):
images, targets = zip(*batch)
return torch.cat([img.reshape(-1, 3, 448, 448) for img in images], 0), targets
def test_collate_fn(batch):
images = batch
return torch.cat([img.reshape(-1, 3, 448, 448) for img in images], 0)
train_loader = DataLoader(train_ds, batch_size=32, shuffle=True, collate_fn=collate_fn)
valid_loader = DataLoader(valid_ds, batch_size=32, shuffle=False, collate_fn=collate_fn)
test_loader = DataLoader(test_ds, batch_size=1, shuffle=False, collate_fn=test_collate_fn)collate_fn에서 targets의 torch.FloatTensor만 제외했습니다.
yolo v1같은 경우에는 target의 형태가 동일했지만 object 개수에 따라 형태가 다른 yolo v2의 경우
ValueError: expected sequence of length 2 at dim 1 (got 4) 이러한 에러가 발생할 수 있습니다.
# Darknet
class Darknet_19(nn.Module):
def __init__(self, num_classes=20, num_bboxes=2):
super(Darknet_19, self).__init__()
self.feature_size = 7
self.num_bboxes=num_bboxes
self.num_classes=num_classes
self.conv = nn.Sequential( # 224x224
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(32),
nn.LeakyReLU(0.1, inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # 112x112
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.1, inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # 56x56
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.1, inplace=True),
nn.Conv2d(in_channels=128, out_channels=64, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.1, inplace=True),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.1, inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), #28x28
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.1, inplace=True),
nn.Conv2d(in_channels=256, out_channels=128, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.1, inplace=True),
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.1, inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), #14x14
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.1, inplace=True),
nn.Conv2d(in_channels=512, out_channels=256, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.1, inplace=True),
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.1, inplace=True),
nn.Conv2d(in_channels=512, out_channels=256, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.1, inplace=True),
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.1, inplace=True), # 43번째 Layer
nn.MaxPool2d(kernel_size=2, stride=2), #7x7
nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU(0.1, inplace=True),
nn.Conv2d(in_channels=1024, out_channels=512, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.1, inplace=True),
nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU(0.1, inplace=True),
nn.Conv2d(in_channels=1024, out_channels=512, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.1, inplace=True),
nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU(0.1, inplace=True),
)
self.classifer = nn.Sequential(
nn.Conv2d(in_channels=1024, out_channels=1000, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(1000),
nn.LeakyReLU(0.1, inplace=True),
nn.AdaptiveAvgPool2d(1),
# nn.Softmax()
)
self.init_weight(self.conv)
self.init_weight(self.classifer)
def forward(self, x):
x = self.conv(x)
x = self.classifer(x)
return x
def init_weight(self, modules):
for m in modules:
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='leaky_relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
DarkNet입니다.
# Yolo v2
class YoLo_v2(nn.Module):
def __init__(self, backbone, num_classes=20,
anchors=[(1.3221, 1.73145), (3.19275, 4.00944), (5.05587, 8.09892), (9.47112, 4.84053),
(11.2364, 10.0071)],):
super(YoLo_v2, self).__init__()
self.anchors = anchors
self.num_classes=num_classes
self.backbone = backbone[:43] # fc layer 제외
self.resconv = backbone[43:]
self.regression = nn.Sequential(
# Skip Connection 1024 + 2048
nn.Conv2d(in_channels=3072, out_channels=1024, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU(0.1, inplace=True),
nn.Conv2d(in_channels=1024, out_channels=(len(anchors) * (5 + num_classes)), kernel_size=1, stride=1, padding=0),
# Activation = Linear
)
self.init_weight(self.regression)
def forward(self, i):
r = self.backbone(i)
batch_size, num_channels, height, width = r.shape
o = self.resconv(r)
r = r.view(-1, num_channels*4, height//2, width//2).contiguous()
x = torch.cat((r, o), 1)
x = self.regression(x)
return x
def init_weight(self, modules):
for m in modules:
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='leaky_relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
Darknet의 구조를 가져오기 때문에 yolo v2 모델 코드는 비교적 짧아졌습니다.
pass through를 위해 변형해줄 때 view로 바꿔줘도 되는지는 모르겠습니다.
4개의 그리드를 channel별로 가지는 방식으로 해주고 싶은데, 구현은 시도해봐야할 것 같습니다.
dark19 = Darknet_19(num_classes=1000)
backbone = dark19.conv
yolov2 = YoLo_v2(backbone=backbone)
yolov2 = yolov2.cuda()
# Loss Function
class YoloLoss(nn.modules.loss._Loss):
# The loss I borrow from LightNet repo.
def __init__(self, num_classes, anchors, reduction=32, coord_scale=1.0, noobject_scale=1.0,
object_scale=5.0, class_scale=1.0, thresh=0.6):
super(YoloLoss, self).__init__()
self.num_classes = num_classes
self.num_anchors = len(anchors)
self.anchor_step = len(anchors[0])
self.anchors = torch.Tensor(anchors)
self.reduction = reduction
self.coord_scale = coord_scale
self.noobject_scale = noobject_scale
self.object_scale = object_scale
self.class_scale = class_scale
self.thresh = thresh
def forward(self, output, target):
batch_size = output.data.size(0)
height = output.data.size(2)
width = output.data.size(3)
# Get x,y,w,h,conf,cls
output = output.view(batch_size, self.num_anchors, -1, height * width)
coord = torch.zeros_like(output[:, :, :4, :])
coord[:, :, :2, :] = output[:, :, :2, :].sigmoid()
coord[:, :, 2:4, :] = output[:, :, 2:4, :]
conf = output[:, :, 4, :].sigmoid()
cls = output[:, :, 5:, :].contiguous().view(batch_size * self.num_anchors, self.num_classes,
height * width).transpose(1, 2).contiguous().view(-1,
self.num_classes)
# Create prediction boxes
pred_boxes = torch.FloatTensor(batch_size * self.num_anchors * height * width, 4)
lin_x = torch.range(0, width - 1).repeat(height, 1).view(height * width)
lin_y = torch.range(0, height - 1).repeat(width, 1).t().contiguous().view(height * width)
anchor_w = self.anchors[:, 0].contiguous().view(self.num_anchors, 1)
anchor_h = self.anchors[:, 1].contiguous().view(self.num_anchors, 1)
if torch.cuda.is_available():
pred_boxes = pred_boxes.cuda()
lin_x = lin_x.cuda()
lin_y = lin_y.cuda()
anchor_w = anchor_w.cuda()
anchor_h = anchor_h.cuda()
pred_boxes[:, 0] = (coord[:, :, 0].detach() + lin_x).view(-1)
pred_boxes[:, 1] = (coord[:, :, 1].detach() + lin_y).view(-1)
pred_boxes[:, 2] = (coord[:, :, 2].detach().exp() * anchor_w).view(-1)
pred_boxes[:, 3] = (coord[:, :, 3].detach().exp() * anchor_h).view(-1)
pred_boxes = pred_boxes.cpu()
# Get target values
coord_mask, conf_mask, cls_mask, tcoord, tconf, tcls = self.build_targets(pred_boxes, target, height, width)
coord_mask = coord_mask.expand_as(tcoord)
tcls = tcls[cls_mask].view(-1).long()
cls_mask = cls_mask.view(-1, 1).repeat(1, self.num_classes)
if torch.cuda.is_available():
tcoord = tcoord.cuda()
tconf = tconf.cuda()
coord_mask = coord_mask.cuda()
conf_mask = conf_mask.cuda()
tcls = tcls.cuda()
cls_mask = cls_mask.cuda()
conf_mask = conf_mask.sqrt()
cls = cls[cls_mask].view(-1, self.num_classes)
# Compute losses
mse = nn.MSELoss(size_average=False)
ce = nn.CrossEntropyLoss(size_average=False)
self.loss_coord = self.coord_scale * mse(coord * coord_mask, tcoord * coord_mask) / batch_size
self.loss_conf = mse(conf * conf_mask, tconf * conf_mask) / batch_size
self.loss_cls = self.class_scale * 2 * ce(cls, tcls) / batch_size
self.loss_tot = self.loss_coord + self.loss_conf + self.loss_cls
return self.loss_tot, self.loss_coord, self.loss_conf, self.loss_cls
def build_targets(self, pred_boxes, ground_truth, height, width):
batch_size = len(ground_truth)
conf_mask = torch.ones(batch_size, self.num_anchors, height * width, requires_grad=False) * self.noobject_scale
coord_mask = torch.zeros(batch_size, self.num_anchors, 1, height * width, requires_grad=False)
cls_mask = torch.zeros(batch_size, self.num_anchors, height * width, requires_grad=False).byte()
tcoord = torch.zeros(batch_size, self.num_anchors, 4, height * width, requires_grad=False)
tconf = torch.zeros(batch_size, self.num_anchors, height * width, requires_grad=False)
tcls = torch.zeros(batch_size, self.num_anchors, height * width, requires_grad=False)
for b in range(batch_size):
if len(ground_truth[b]) == 0:
continue
# Build up tensors
cur_pred_boxes = pred_boxes[
b * (self.num_anchors * height * width):(b + 1) * (self.num_anchors * height * width)]
if self.anchor_step == 4:
anchors = self.anchors.clone()
anchors[:, :2] = 0
else:
anchors = torch.cat([torch.zeros_like(self.anchors), self.anchors], 1)
gt = torch.zeros(len(ground_truth[b]), 4)
for i, anno in enumerate(ground_truth[b]):
gt[i, 0] = (anno[0] + anno[2] / 2) / self.reduction
gt[i, 1] = (anno[1] + anno[3] / 2) / self.reduction
gt[i, 2] = anno[2] / self.reduction
gt[i, 3] = anno[3] / self.reduction
# Set confidence mask of matching detections to 0
iou_gt_pred = bbox_ious(gt, cur_pred_boxes)
mask = (iou_gt_pred > self.thresh).sum(0) >= 1
conf_mask[b][mask.view_as(conf_mask[b])] = 0
# Find best anchor for each ground truth
gt_wh = gt.clone()
gt_wh[:, :2] = 0
iou_gt_anchors = bbox_ious(gt_wh, anchors)
_, best_anchors = iou_gt_anchors.max(1)
# Set masks and target values for each ground truth
for i, anno in enumerate(ground_truth[b]):
gi = min(width - 1, max(0, int(gt[i, 0])))
gj = min(height - 1, max(0, int(gt[i, 1])))
best_n = best_anchors[i]
iou = iou_gt_pred[i][best_n * height * width + gj * width + gi]
coord_mask[b][best_n][0][gj * width + gi] = 1
cls_mask[b][best_n][gj * width + gi] = 1
conf_mask[b][best_n][gj * width + gi] = self.object_scale
tcoord[b][best_n][0][gj * width + gi] = gt[i, 0] - gi
tcoord[b][best_n][1][gj * width + gi] = gt[i, 1] - gj
tcoord[b][best_n][2][gj * width + gi] = math.log(max(gt[i, 2], 1.0) / self.anchors[best_n, 0])
tcoord[b][best_n][3][gj * width + gi] = math.log(max(gt[i, 3], 1.0) / self.anchors[best_n, 1])
tconf[b][best_n][gj * width + gi] = iou
tcls[b][best_n][gj * width + gi] = int(anno[4])
return coord_mask, conf_mask, cls_mask, tcoord, tconf, tcls
def bbox_ious(boxes1, boxes2):
b1x1, b1y1 = (boxes1[:, :2] - (boxes1[:, 2:4] / 2)).split(1, 1)
b1x2, b1y2 = (boxes1[:, :2] + (boxes1[:, 2:4] / 2)).split(1, 1)
b2x1, b2y1 = (boxes2[:, :2] - (boxes2[:, 2:4] / 2)).split(1, 1)
b2x2, b2y2 = (boxes2[:, :2] + (boxes2[:, 2:4] / 2)).split(1, 1)
dx = (b1x2.min(b2x2.t()) - b1x1.max(b2x1.t())).clamp(min=0)
dy = (b1y2.min(b2y2.t()) - b1y1.max(b2y1.t())).clamp(min=0)
intersections = dx * dy
areas1 = (b1x2 - b1x1) * (b1y2 - b1y1)
areas2 = (b2x2 - b2x1) * (b2y2 - b2y1)
unions = (areas1 + areas2.t()) - intersections
return intersections / unionsloss를 위한 class입니다.
build targets로 ground truth를 변형해주고, forward에서 loss를 계산하게 됩니다.
# Optimizer
criterion = YoloLoss(num_classes, yolov2.anchors)
optimizer = optim.SGD(yolov2.parameters(), lr=1e-3, momentum=0.9, weight_decay=5e-4)
def update_lr(optimizer, epoch, burnin_exp=4.0):
if epoch == 0:
lr = 1e-3
elif epoch == 80:
lr = 1e-4
elif epoch == 110:
lr = 1e-5
else: return
for param_group in optimizer.param_groups:
param_group['lr'] = lr
논문에 나온대로
loss function, optimizer, lr scheduler를 구현했습니다.
# Training
epochs = 160
lt = len(train_ds)
lv = len(valid_ds)
bl = len(train_loader)
vl = len(valid_loader)
best_loss = 1e9
best_epoch = 0
min_change = 0.0
early_stop = 3
start_time = time.time()
train_history = {'total_loss':[], 'loss_coord':[], 'loss_conf':[], 'loss_cls':[]}
valid_history = {'total_loss':[], 'loss_coord':[], 'loss_conf':[], 'loss_cls':[]}
for epoch in range(epochs):
t_loss, t_loss_coord, t_loss_conf, t_loss_cls = 0, 0, 0, 0
yolov2.train()
tk0 = tqdm(train_loader, total=bl,leave=False)
for step, (images, targets) in enumerate(tk0, 0):
images = images.cuda()
update_lr(optimizer, epoch, epoch/4)
outputs = yolov2(images)
loss, loss_coord, loss_conf, loss_cls = criterion(outputs, targets)
# zero the parameter gradients
optimizer.zero_grad()
loss.backward()
optimizer.step()
t_loss += loss.item()
t_loss_coord += loss_coord.item()
t_loss_conf += loss_conf.item()
t_loss_cls += loss_cls.item()
train_history['total_loss'].append(t_loss/lt)
train_history['loss_coord'].append(t_loss_coord/lt)
train_history['loss_conf'].append(t_loss_conf/lt)
train_history['loss_cls'].append(t_loss_cls/lt)
print("[Train - Epoch: {}/{}] Lr: {} Loss:{:.2f} (Coord:{:.2f} Conf:{:.2f} Cls:{:.2f})".format(
epoch + 1,
epochs,
optimizer.param_groups[0]['lr'],
t_loss,
t_loss_coord,
t_loss_conf,
t_loss_cls))
tv_loss, tv_loss_coord, tv_loss_conf, tv_loss_cls = 0, 0, 0, 0
yolov2.eval()
tk0 = tqdm(valid_loader, total=vl,leave=False)
for step, (images, targets) in enumerate(tk0, 0):
images = images.cuda()
with torch.no_grad():
outputs = yolov2(images)
loss, loss_coord, loss_conf, loss_cls = criterion(outputs, targets)
tv_loss += loss.item()
tv_loss_coord += loss_coord.item()
tv_loss_conf += loss_conf.item()
tv_loss_cls += loss_cls.item()
valid_history['total_loss'].append(tv_loss/lv)
valid_history['loss_coord'].append(tv_loss_coord/lv)
valid_history['loss_conf'].append(tv_loss_conf/lv)
valid_history['loss_cls'].append(tv_loss_cls/lv)
print("[Valid - Epoch: {}/{}] Loss:{:.2f} (Coord:{:.2f} Conf:{:.2f} Cls:{:.2f})".format(
epoch + 1,
epochs,
tv_loss,
tv_loss_coord,
tv_loss_conf,
tv_loss_cls))
# Save Model
if tv_loss + min_change < best_loss:
best_loss = tv_loss
best_epoch = epoch
# torch.save(model, opt.saved_path + os.sep + "trained_yolo_voc")
torch.save(yolov2.state_dict(), save_dir + "/yolov2.pth")
# torch.save(model, opt.saved_path + os.sep + "whole_model_trained_yolo_voc")
# Early stopping
# if epoch - best_epoch > early_stop > 0:
# print("Stop training at epoch {}. The lowest loss achieved is {}".format(epoch, tv_loss))
# break
학습을 위한 함수입니다.
기존에 사용하던 코드에서, reference에 있는 pytorch 구현 github 학습 함수를 참고해서
model saving과 early stopping을 가져왔습니다.
# 결론
1. YoLo 학습 결과 (이미지 테스팅)
colab에서 학습 진행 중
2. 비디오 테스팅
colab 학습 진행 중
3. PIL vs cv2 속도 비교
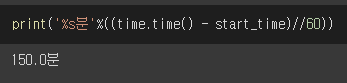
cv2 160 epoch 학습 총 소요 시간

PIL 160 epoch 학습 총 소요 시간
감사합니당
Ref.
'데이터 분석 > 딥러닝' 카테고리의 다른 글
| [YoLo v1] 논문 리뷰 & 구현 (Pytorch) (13) | 2021.01.01 |
|---|---|
| [Faster R-CNN] 논문 리뷰 & 구현 (Pytorch) (1) | 2020.12.30 |
| [R-CNN] 논문 리뷰 & 구현 (Pytorch) (0) | 2020.12.23 |